

“Right-scaling” clusters
Jun Mukai - Member of Technical Staff, CloudNatix
Date: Nov 17, 2023
What is the “right-scaling” of a cluster?
When setting up a Kubernetes cluster, you need to specify the type of node instances and the quantity of nodes for each type. Alternatively, you can configure autoscaling for the node count. However, determining the correct configuration can be challenging due to the abundance of tuning options. For example, there are usually hundreds of instance types available.
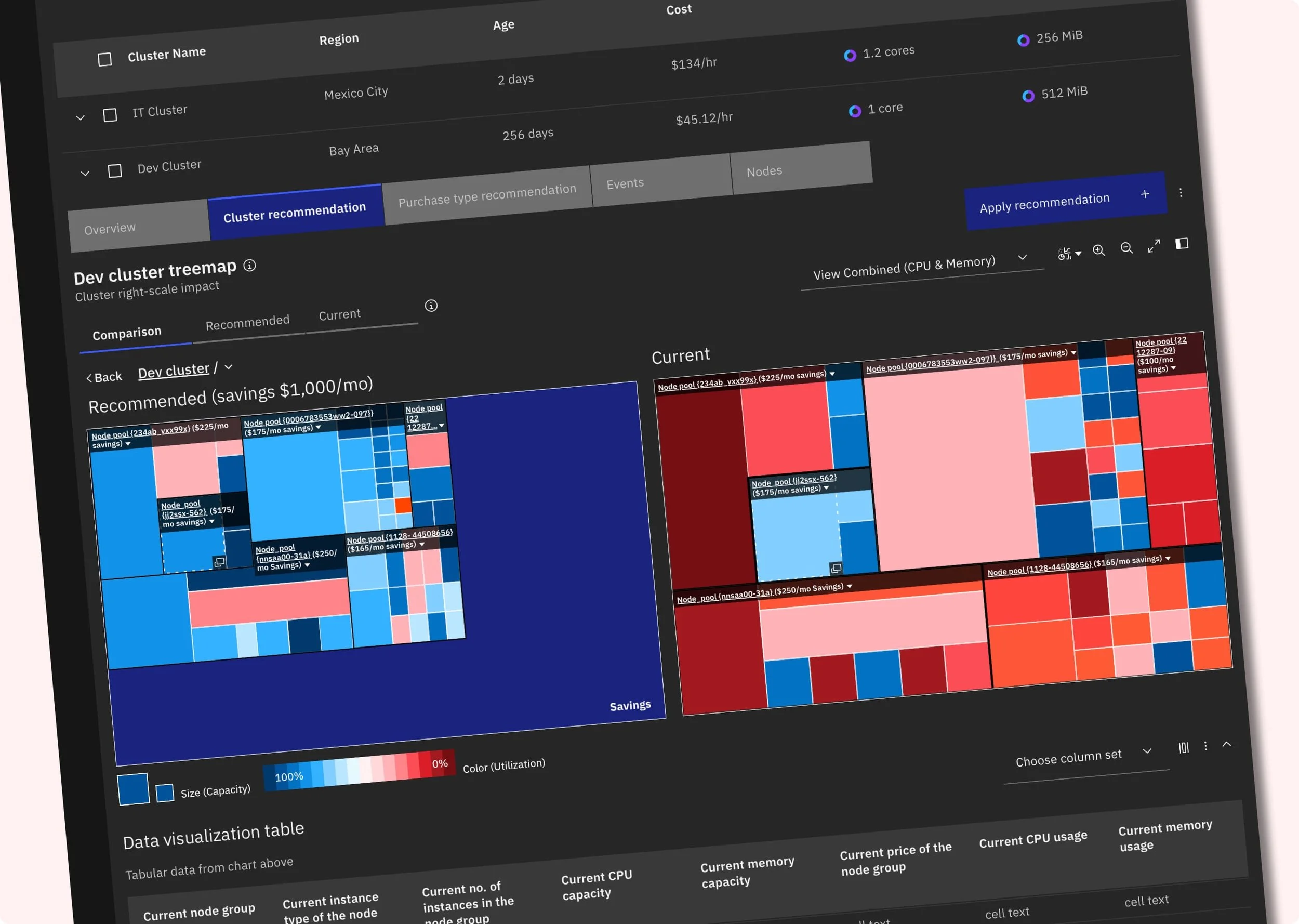
Our cluster-rightscaler is a solution to this problem. It analyzes workloads within the cluster and dynamically creates the optimal number of nodes with corresponding instance types. This ensures sufficient computing resources while optimizing the total cost of the nodes.
This blog post will delve into the challenges posed by this problem and discuss the design choices we made in developing cluster-rightscaler.
Reactive vs Full scheduling
To explore instance types and other computing resources, there are two approaches: the reactive approach and the full-scheduling approach.
The reactive approach observes newly scheduled workloads and explores the optimal set of instance types for these new workloads. Current workloads are non-customizable and not subject to optimization.
Alternatively, full-scheduling explores the entire set of workloads, including existing ones. It can relocate all workloads and modify any nodes, essentially treating the cluster as if it were newly created.
For cluster-rightscaler, we opted for the full-scheduling approach. While this demands more computing resources for generating recommended configurations and incurs additional cost for data management for workloads (especially given the dynamic nature of some workloads, leading to a potentially large number of short-lived instances), it offers the capability to comprehensively optimize the entire cluster, resulting in superior outcomes.
Computational complexity
Even when all the information about the workloads in a cluster is available, determining the optimal configuration for the number of nodes to be allocated for each type of instance remains challenging. While I won't delve into the complete algorithmic details, here's a brief summary.
There are two inherent complexity challenges in this scenario. Firstly, given the list of workloads and the set of possible instance types, the system needs to simulate the scheduling of these workloads to the nodes and then estimate the total cost of the cluster. It can then compare which set of instance types is more cost-effective than others. However, this simulation is inherently challenging. In computer science literature, this simulation problem is known as the “bin-packing” problem, recognized as “NP-hard” – a term that may not be easily explained without computer science jargon, but essentially indicates the impossibility of finding the best allocation. Fortunately, several "not-so-bad" heuristic algorithms exist, and we implemented one such simple heuristic algorithm for the scheduling simulation.
Secondly, intelligently selecting instance types poses a challenge, especially considering a cloud provider may offer hundreds of possible instance types. If a cluster has 10 nodes and a CSP has 100 possible instance types, the potential combinations would be on the order of 10^100. Searching through such an extensive number of combinations is impractical. Instead, we’ve introduced several assumptions to narrow down the possibilities. For example, cluster-rightscaler groups nodes into node groups, and it assigns a single instance type to each node group. Additionally, we’ve implemented another heuristic algorithm to avoid exhaustive searches across all possible combinations of these node groups. While the end result of this algorithm may not be theoretically optimal, it delivers substantial cost savings through rigorous analysis past what can be expected of a human.
In addition to these theoretical complexities to the bin packing problem, there are additional complexities we must address, like scheduling parameters of Kubernetes. For example, you can specify particular properties of nodes for the workloads (e.g. OS, CPU architecture, node-groups, purchase types like spot-instance or on-demand), as well as coexistence requirements among pods (e.g. this type of pod needs to coexist within the same node, or these pods need to reside on different nodes). Without accounting for these parameters, the recommended configuration would be unacceptable to the end user.
Pre-generation of the recommendations
As mentioned earlier, finding the right configuration for a single cluster is complex and time-consuming. To address the need for on-demand recommendations, we've implemented a backend service that periodically collects the cluster's data and pre-generates the results. This hourly pre-generation process covers all clusters, storing the data in a database. This enables us to swiftly visualize recommended configurations whenever the user wishes to view them.
This approach also enables us to reduce the risk of encountering issues when users apply the provided recommendations. Due to the dynamic nature of Kubernetes workloads, a recommendation that is optimal at one point may not adequately allocate computing resources at another time. Among the recommendations accumulated over time, cluster-rightscaler offers the least effective solution to users. By doing so, it helps mitigate the risk of failing to achieve the promised cost optimization.
Customizations and further experiments
Once the recommended configuration is prepared for the users, what is the next step? Apply it directly? While we hope that would be the case, clusters often have additional requirements or conditions not directly visible from workloads or node specifications. For example, a cluster may have savings plans, in which case the instance types in these plans should take precedence. Therefore cluster-rightscaler allows customization of several parameters for its scheduling simulations, such as limiting instance types or their sizes. When these parameters are set, the system runs a new scheduling simulation and provides a one-shot experiment result. Users can review the result and make further experiments with different customization parameters. Additionally, customization parameters can be stored in our backend database, allowing cluster-rightscaler to pre-generate recommendations with that combination of parameters.
This type of customization also enables you to conduct experiments and estimations for environmental changes. One example is the switch to ARM architecture. When a cluster fully switches from x86 to ARM, what will be the cost implications? Cluster-rightscaler performs a scheduling simulation using only ARM instance types and can generate the “best” configurations under that condition, offering insights into such questions.
At CloudNatix, we have developed cluster-rightsizing recommendations as a means to save customers money and as a way to provide what-if analysis adds value for end users.